7. ルールベースモデリング入門¶
E-Cell4は、ルールベースモデリング環境を提供します。
In [1]:
%matplotlib inline
from ecell4 import *
7.1. Species.count¶
まず、Speciesはcount関数を提供します。
Species.count は Species の間でマッチした数を数えます。
In [2]:
sp1 = Species("A(b^1).B(b^1)")
sp2 = Species("A(b^1).A(b^1)")
pttrn1 = Species("A")
print(pttrn1.count(sp1)) # => 1
print(pttrn1.count(sp2)) # => 2
1
2
上記の場合、Species.countはサイトには関係なく Species の
A という名前の UnitSpecies の数を返します。
結合の有無の状態を明確にする場合は下記のようになります。
In [3]:
pttrn1 = Species("A(b)")
pttrn2 = Species("A(b^_)")
print(pttrn1.count(sp1)) # => 0
print(pttrn2.count(sp1)) # => 1
0
1
ここでA(b)は結合bが空いていることを示唆し、A(b^_)は結合bが有ることを意味します。
アンダースコア _はワイルドカードを意味します。
同様に、サイトの状態を指定することもできます。
In [4]:
sp1 = Species("A(b=u)")
pttrn1 = Species("A(b)")
pttrn2 = Species("A(b=u)")
print(pttrn1.count(sp1)) # => 1
print(pttrn2.count(sp1)) # => 1
1
1
A(b)は状態については何も言いませんが、
A(b=u)は状態と結合の両方をその分子の条件として明記します。
A(b=u)は、Aという名前の
UnitSpeciesが状態がuで結合が空である
bというサイトを持つことを意味します。 ワイルドカード
_は状態と名前両方で用いることが可能です。
In [5]:
sp1 = Species("A(b=u^1).B(b=p^1)")
pttrn1 = Species("A(b=_^_)") # This is equivalent to `A(b^_)` here
pttrn2 = Species("_(b^_)")
print(pttrn1.count(sp1)) # => 1
print(pttrn2.count(sp1)) # => 2
1
2
ワイルドカード _ は何にでもマッチし、マッチしたパターンは
Species でもワイルドカード間で一貫しません。
一方、名前付きのワイルドカード _1 、_2
などは、マッチ内の一貫性を与えます。
In [6]:
sp1 = Species("A(b^1).B(b^1)")
pttrn1 = Species("_._")
pttrn2 = Species("_1._1")
print(pttrn1.count(sp1)) # => 2
print(pttrn2.count(sp1)) # => 0
2
0
最初のパターンは2つの方法(A.B と
B.A)でマッチしますが、2番目のパターンは何もマッチしません。
Species.countは対称の場合でも常に UnitSpecies
の順序を区別します。 したがって、 _1._1 は二量体の数を意味しません。
In [7]:
sp1 = Species("A(b^1).A(b^1)")
pttrn1 = Species("_1._1")
print(pttrn1.count(sp1)) # => 2
2
7.2. ReactionRule.count と ReactionRule.generate¶
ReactionRule
はまた、与えられたreactantsのリストとのマッチ数をカウントする機能を持っています。
In [8]:
rr1 = create_unimolecular_reaction_rule(Species("A(p=u)"), Species("A(p=p)"), 1.0)
sp1 = Species("A(b^1,p=u).B(b^1)")
print(rr1.count([sp1])) # => 1
1
ReactionRule.generate は、マッチ情報に基づいて生成された
ReactionRule のリストを返します。
In [9]:
print([rr.as_string() for rr in rr1.generate([sp1])])
[u'A(b^1,p=u).B(b^1)>A(b^1,p=p).B(b^1)|1']
ReactionRule.generate は与えられたリストの中のSpecies
の順番で結果が違ってきます:
In [10]:
rr1 = create_binding_reaction_rule(Species("A(b)"), Species("B(b)"), Species("A(b^1).B(b^1)"), 1.0)
sp1 = Species("A(b)")
sp2 = Species("B(b)")
print([rr.as_string() for rr in rr1.generate([sp1, sp2])])
print([rr.as_string() for rr in rr1.generate([sp2, sp1])])
[u'A(b)+B(b)>A(b^1).B(b^1)|1']
[]
現在の実装では、 ReactionRule.generate は常に一意の ReactionRule
のリストを返すわけではありません。
In [11]:
sp1 = Species("A(b,c^1).A(b,c^1)")
sp2 = Species("B(b,c^1).B(b,c^1)")
print(rr1.count([sp1, sp2])) # => 4
print([rr.as_string() for rr in rr1.generate([sp1, sp2])])
4
[u'A(b,c^1).A(b,c^1)+B(b,c^1).B(b,c^1)>A(b^1,c^2).A(b,c^2).B(b^1,c^3).B(b,c^3)|1', u'A(b,c^1).A(b,c^1)+B(b,c^1).B(b,c^1)>A(b^1,c^2).A(b,c^2).B(b,c^3).B(b^1,c^3)|1', u'A(b,c^1).A(b,c^1)+B(b,c^1).B(b,c^1)>A(b,c^1).A(b^2,c^1).B(b^2,c^3).B(b,c^3)|1', u'A(b,c^1).A(b,c^1)+B(b,c^1).B(b,c^1)>A(b,c^1).A(b^2,c^1).B(b,c^3).B(b^2,c^3)|1']
上に挙げた ReactionRules
は異なって見えますが、すべての結果は同じことを示しています。
In [12]:
print(set([unique_serial(rr.products()[0]) for rr in rr1.generate([sp1, sp2])]))
set([u'A(b,c^1).A(b^2,c^1).B(b^2,c^3).B(b,c^3)'])
これは、これらの ReactionRule は、同じ Species
を生成するとはいえ、異なるマッチ情報に基づいて生成されるために起こります。
詳細については、以下のセクションを参照してください。
ワイルドカードは ReactionRule でも利用できます。
In [13]:
rr1 = create_unimolecular_reaction_rule(Species("A(p=u^_)"), Species("A(p=p^_)"), 1.0)
print([rr.as_string() for rr in rr1.generate([Species("A(p=u^1).B(p^1)")])])
[u'A(p=u^1).B(p^1)>A(p=p^1).B(p^1)|1']
もちろん、ワイルドカードは
UnitSpeciesの名前として受け入れられます。
In [14]:
rr1 = create_unimolecular_reaction_rule(Species("_(p=u)"), Species("_(p=p)"), 1.0)
print([rr.as_string() for rr in rr1.generate([Species("A(p=u)")])])
print([rr.as_string() for rr in rr1.generate([Species("B(b^1,p=u).C(b^1,p=u)")])])
[u'A(p=u)>A(p=p)|1']
[u'B(b^1,p=u).C(b^1,p=u)>B(b^1,p=p).C(b^1,p=u)|1', u'B(b^1,p=u).C(b^1,p=u)>B(b^1,p=u).C(b^1,p=p)|1']
State中での名前付きワイルドカードは、サイト間の対応を指定するのに便利です。
In [15]:
rr1 = create_unbinding_reaction_rule(Species("AB(a=_1, b=_2)"), Species("B(b=_2)"), Species("A(a=_1)"), 1.0)
print([rr.as_string() for rr in rr1.generate([Species("AB(a=x, b=y)")])])
print([rr.as_string() for rr in rr1.generate([Species("AB(a=y, b=x)")])])
[u'AB(a=x,b=y)>B(b=y)+A(a=x)|1']
[u'AB(a=y,b=x)>B(b=x)+A(a=y)|1']
無名ワイルドカード _ は、マッチの間の等価性を気にしません。
Products は順番に生成されます。
In [16]:
rr1 = create_binding_reaction_rule(Species("_(b)"), Species("_(b)"), Species("_(b^1)._(b^1)"), 1.0)
print(rr1.as_string())
print([rr.as_string() for rr in rr1.generate([Species("A(b)"), Species("A(b)")])])
print([rr.as_string() for rr in rr1.generate([Species("A(b)"), Species("B(b)")])])
_(b)+_(b)>_(b^1)._(b^1)|1
[u'A(b)+A(b)>A(b^1).A(b^1)|1']
[u'A(b)+B(b)>A(b^1).B(b^1)|1']
その対称性のために、上記のセルの前者の場合は元の反応速度の半分となるように設定されることが望ましい場合があります。
これは 後者の分子の組み合わせの数は 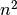 ではありますが,前者の分子の組み合わせの数が
ではありますが,前者の分子の組み合わせの数が 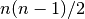 であるためです。 (ここでAとBの両方の分子の数は
であるためです。 (ここでAとBの両方の分子の数は 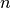 です。)
またこれは
です。)
またこれは gillespie と ode に当てはまります。
しかし、egfrd と spatiocyte
では、反応速度は固有のものであり、組み合わせの数には影響されません
(したがって、E-Cell4では、その場合でも速度の変更は行われません。)。
アルゴリズムの違いについては、 Homodimerization and Annihilation を参照してください。
名前のないワイルドカードとは対照的に、名前付けされたワイルドカードは名前付けされたワイルドカード同士での整合性を保持し、
ReactionRule で常に同じ値を示します。
In [17]:
rr1 = create_binding_reaction_rule(Species("_1(b)"), Species("_1(b)"), Species("_1(b^1)._1(b^1)"), 1.0)
print(rr1.as_string())
print([rr.as_string() for rr in rr1.generate([Species("A(b)"), Species("A(b)")])])
print([rr.as_string() for rr in rr1.generate([Species("A(b)"), Species("B(b)")])]) # => []
_1(b)+_1(b)>_1(b^1)._1(b^1)|1
[u'A(b)+A(b)>A(b^1).A(b^1)|1']
[]
名前付きのワイルドカードは、 UnitSpecies と site
の名前の間でも厳密に整合性を保持しています。
In [18]:
rr1 = create_binding_reaction_rule(Species("A(b=_1)"), Species("_1(b)"), Species("A(b=_1^1)._1(b^1)"), 1.0)
print(rr1.as_string())
print([rr.as_string() for rr in rr1.generate([Species("A(b=B)"), Species("A(b)")])]) # => []
print([rr.as_string() for rr in rr1.generate([Species("A(b=B)"), Species("B(b)")])])
A(b=_1)+_1(b)>A(b=_1^1)._1(b^1)|1
[]
[u'A(b=B)+B(b)>A(b=B^1).B(b^1)|1']
7.3. NetfreeModel¶
NetfreeModelはルールベースモデリングのためのModelクラスです。
NetfreeModel のインターフェースは NetworkModel
とほぼ同じですが、ルールとマッチを考慮しています。
In [19]:
rr1 = create_binding_reaction_rule(Species("A(r)"), Species("A(l)"), Species("A(r^1).A(l^1)"), 1.0)
m1 = NetfreeModel()
m1.add_reaction_rule(rr1)
print(m1.num_reaction_rules())
m2 = NetworkModel()
m2.add_reaction_rule(rr1)
print(m2.num_reaction_rules())
1
1
2. モデルを構築する方法 で説明したPythonの表記法はここでも利用可能です。
モデルを NetfreeModel として取得するには、get_model 関数で
is_netfree オプションを True に設定します。
In [20]:
with reaction_rules():
A(r) + A(l) > A(r^1).A(l^1) | 1.0
m1 = get_model(is_netfree=True)
print(repr(m1))
<ecell4.core.NetfreeModel object at 0x7fbb44dc7708>
Model.query_reaction_rules は、与えられた反応物に対する
ReactionRule のリストを返します。
NetworkModel は Species の等価性に基づいて ReactionRule
を返します。
In [21]:
print(len(m2.query_reaction_rules(Species("A(r)"), Species("A(l)")))) # => 1
print(len(m2.query_reaction_rules(Species("A(l,r)"), Species("A(l,r)")))) # => 0
1
0
一方、 NetfreeModel は、格納された ReactionRule
をルールベースの方法に適用することによってリストを生成します。
In [22]:
print(len(m1.query_reaction_rules(Species("A(r)"), Species("A(l)")))) # => 1
print(len(m1.query_reaction_rules(Species("A(l,r)"), Species("A(l,r)")))) # => 1
1
1
NetfreeModel は生成されたオブジェクトをキャッシュしません。
したがって、 NetfreeModel.query_reaction_rules
は遅いですが、より少ないメモリしか必要としません。
In [23]:
print(m1.query_reaction_rules(Species("A(l,r)"), Species("A(l,r)"))[0].as_string())
print(m1.query_reaction_rules(Species("A(l,r^1).A(l^1,r)"), Species("A(l,r)"))[0].as_string())
print(m1.query_reaction_rules(Species("A(l,r^1).A(l^1,r)"), Species("A(l,r^1).A(l^1,r)"))[0].as_string())
A(l,r)+A(l,r)>A(l,r^1).A(l^1,r)|2
A(l,r^1).A(l^1,r)+A(l,r)>A(l,r^1).A(l^1,r^2).A(l^2,r)|2
A(l,r^1).A(l^1,r)+A(l,r^1).A(l^1,r)>A(l,r^1).A(l^1,r^2).A(l^2,r^3).A(l^3,r)|2
NetfreeModel.expand は与えられたシードに対して繰り返し
Reaction Rules を適用することによって
NetfreeModelをNetworkModelに展開します。
In [24]:
with reaction_rules():
_(b) + _(b) == _(b^1)._(b^1) | (1.0, 1.0)
m3 = get_model(True)
print(m3.num_reaction_rules())
m4 = m3.expand([Species("A(b)"), Species("B(b)")])
print(m4.num_reaction_rules())
print([rr.as_string() for rr in m4.reaction_rules()])
2
6
[u'A(b)+A(b)>A(b^1).A(b^1)|1', u'A(b)+B(b)>A(b^1).B(b^1)|1', u'B(b)+B(b)>B(b^1).B(b^1)|1', u'A(b^1).A(b^1)>A(b)+A(b)|1', u'A(b^1).B(b^1)>A(b)+B(b)|1', u'B(b^1).B(b^1)>B(b)+B(b)|1']
展開の無限ループを避けるために、繰り返しの上限と Species における
UnitSpecies の数の上限を制限することができます。
In [25]:
m2 = m1.expand([Species("A(l, r)")], 100, {Species("A"): 4})
print(m2.num_reaction_rules()) # => 4
print([rr.as_string() for rr in m2.reaction_rules()])
4
[u'A(l,r)+A(l,r)>A(l,r^1).A(l^1,r)|2', u'A(l,r^1).A(l^1,r)+A(l,r^1).A(l^1,r)>A(l,r^1).A(l^1,r^2).A(l^2,r^3).A(l^3,r)|2', u'A(l,r)+A(l,r^1).A(l^1,r)>A(l,r^1).A(l^1,r^2).A(l^2,r)|2', u'A(l,r)+A(l,r^1).A(l^1,r^2).A(l^2,r)>A(l,r^1).A(l^1,r^2).A(l^2,r^3).A(l^3,r)|2']
7.4. Species, ReactionRule そして NetfreeModel の違い¶
上記で説明した機能は似ていますが、基準にはいくつかの違いがあります。
In [26]:
sp1 = Species("A(b^1).A(b^1)")
sp2 = Species("A(b)")
rr1 = create_unbinding_reaction_rule(sp1, sp2, sp2, 1.0)
print(sp1.count(sp1))
print([rr.as_string() for rr in rr1.generate([sp1])])
2
[u'A(b^1).A(b^1)>A(b)+A(b)|1']
Species.count はマッチングのための2つの異なる方向(左から右 と
右から左)を示唆していますが、 ReactionRule.generate はたった1つの
ReactionRuleしか返しません。なぜならその順は生成物に影響しないからです。
In [27]:
sp1 = Species("A(b^1).B(b^1)")
rr1 = create_unbinding_reaction_rule(
sp1, Species("A(b)"), Species("B(b)"), 1.0)
sp2 = Species("A(b^1,c^2).A(b^3,c^2).B(b^1).B(b^3)")
print(sp1.count(sp2))
print([rr.as_string() for rr in rr1.generate([sp2])])
2
[u'A(b^1,c^2).A(b^3,c^2).B(b^1).B(b^3)>A(b,c^1).A(b^2,c^1).B(b^2)+B(b)|1', u'A(b^1,c^2).A(b^3,c^2).B(b^1).B(b^3)>A(b^1,c^2).A(b,c^2).B(b^1)+B(b)|1']
この場合、 ReactionRule.generate は Species.count
と同様に動作します。
しかし、 Netfree.query_reaction_rules
はより速い反応速度を持つたった一つの ReationRule を返します:
In [28]:
m1 = NetfreeModel()
m1.add_reaction_rule(rr1)
print([rr.as_string() for rr in m1.query_reaction_rules(sp2)])
[u'A(b^1,c^2).A(b^3,c^2).B(b^1).B(b^3)>A(b,c^1).A(b^2,c^1).B(b^2)+B(b)|2']
NetfreeModel.query_reaction_rules は、生成された各 ReactionRule
が他と同じかどうかをチェックし、可能ならばそれを集約します。
上で説明したように、 ReactionRule.generate は Species
の順序次第で結果が異なりますが、
Netfree.query_reaction_rulesはそうではありません。
In [29]:
sp1 = Species("A(b)")
sp2 = Species("B(b)")
rr1 = create_binding_reaction_rule(sp1, sp2, Species("A(b^1).B(b^1)"), 1.0)
m1 = NetfreeModel()
m1.add_reaction_rule(rr1)
print([rr.as_string() for rr in rr1.generate([sp1, sp2])])
print([rr.as_string() for rr in m1.query_reaction_rules(sp1, sp2)])
print([rr.as_string() for rr in rr1.generate([sp2, sp1])]) # => []
print([rr.as_string() for rr in m1.query_reaction_rules(sp2, sp1)])
[u'A(b)+B(b)>A(b^1).B(b^1)|1']
[u'A(b)+B(b)>A(b^1).B(b^1)|1']
[]
[u'B(b)+A(b)>A(b^1).B(b^1)|1']
名前のないワイルドカードは、一致していなければなりませんが、名前のないワイルドカードは必ずしも一致している必要はありません。
In [30]:
sp1 = Species("_(b)")
sp2 = Species("_1(b)")
sp3 = Species("A(b)")
sp4 = Species("B(b)")
rr1 = create_binding_reaction_rule(sp1, sp1, Species("_(b^1)._(b^1)"), 1)
rr2 = create_binding_reaction_rule(sp2, sp2, Species("_1(b^1)._1(b^1)"), 1)
print(sp1.count(sp2)) # => 1
print(sp1.count(sp3)) # => 1
print(sp2.count(sp2)) # => 1
print(sp2.count(sp3)) # => 1
print([rr.as_string() for rr in rr1.generate([sp3, sp3])])
print([rr.as_string() for rr in rr1.generate([sp3, sp4])])
print([rr.as_string() for rr in rr2.generate([sp3, sp3])])
print([rr.as_string() for rr in rr2.generate([sp3, sp4])]) # => []
1
1
1
1
[u'A(b)+A(b)>A(b^1).A(b^1)|1']
[u'A(b)+B(b)>A(b^1).B(b^1)|1']
[u'A(b)+A(b)>A(b^1).A(b^1)|1']
[]